Portfolio item number 1
Short description of portfolio item number 1

Short description of portfolio item number 1
Short description of portfolio item number 2
Published in , 2022
A semi-supervised multi-scale training framework that applies consistency regularization across decoder layers to use unlabeled data for medical image segmentation.
![[Preprint] A MuST for Consistency Regularization in Semi-Supervised Medical Image Segmentation](/files/paper_files/MuST/thumbnail.png)
Published in The 34th British Machine Vision Conference (BMVC), 2023
Language-guided consistency learning enables semantically rich and robust visual represntation significanlty improve domain generalization in object detection without requiring labeled data from multiple domains.

Published in IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
We analyze how context in class text representations of VL models affects geographical robustness in object recognition. We propose to learn robust soft prompts by regularizing world knowledge from LLMs without using in data from target domain.
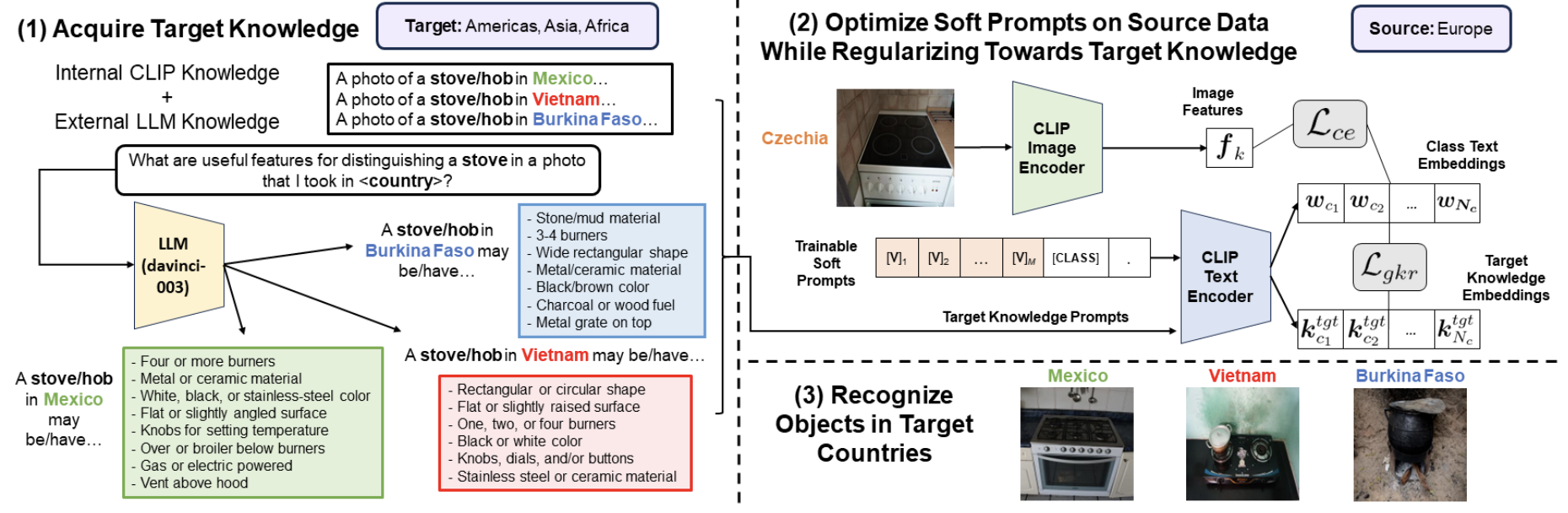
Published in IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2025
We study how vision–language models interpret persuasive advertisements with atypical portrayal of objects. We introduce 3 new tasks to evaluate the visual reasoning abilities of VLMs and MLLMs in understanding atypical imagery. We further compare the visual reasoning capabilities of VLMs and LLMs via purposing an atypicality-aware chain-of-thought prompting method. Our findings show that current VLMs and MLLMs struggle with reasoning over atypical images in creative ads and tend to rely on shallow visual cues (e.g., object recognition), leading to significantly more semantic errors than LLMs when faced with semantically challenging negatives.

Published in The Thirty-Ninth Annual Conference on Neural Information Processing Systems (NeurIPS), 2025
This work introduces RoleBench, a benchmark for evaluating compositional generalization in text-to-image models through action-based relations. It identifies a systematic failure—RoleCollapse—where models default to frequent reversed relations, and shows that a lightweight intermediate fine-tuning approach (ReBind) can significantly reduce role bias and improve compositional generation.

Published in The Fourteenth International Conference on Learning Representations (ICLR), 2026
This paper introduces CULTIVate, a benchmark for evaluating cultural faithfulness in text-to-image models using cross-cultural everyday activities. It proposes descriptor-based metrics to measure cultural alignment, hallucination, and exaggeration, and shows that current models perform unevenly across regions, with stronger results for Global North cultures.

Published:
This is a description of your talk, which is a markdown files that can be all markdown-ified like any other post. Yay markdown!
Published:
This is a description of your conference proceedings talk, note the different field in type. You can put anything in this field.
Undergraduate course, University 1, Department, 2014
This is a description of a teaching experience. You can use markdown like any other post.
Workshop, University 1, Department, 2015
This is a description of a teaching experience. You can use markdown like any other post.